python3.6编写,网站目录遍历程序,可以扫描目标网站所有的文件和文件夹,目录遍历爬虫
”python3 目录遍历 网站目录 爬虫“ 的搜索结果
(引用自百度百科)爬取网站在此笔者爬取了神印王座,神印王座全文阅读 已完结 – 唐家三少作品网站上的一部小说,一下是该源网址打开后的章节目录。接下来,我们便打开其网址的源代码:我们看到源代...
标题有点夸张,我最终的目的其实是:用 Python 从指定网页下载 centos7.6.1810 所有 src.rpm 源码包(我找过 centos 的镜像,都无一例外没有源码包目录,感觉很不人性化,而且网页上的源码文件也没有统一在一个目录...
Python目录遍历参考链接:https://www.leavesongs.com/PYTHON/pythonfile.html1.作用查找黑客上传的webshell2.开头添加# -*- coding=UTF-8 -*-,可以#加中文不报错3.多行注释选中代码,按住ctrl+/多行注释4.代码# -*- ...
遵守规则: 为避免对网站造成过大负担或触发反爬虫机制,爬虫需要遵守网站的robots.txt协议,限制访问频率和深度,并模拟人类访问行为,如设置User-Agent。 反爬虫应对: 由于爬虫的存在,一些网站采取了反爬虫措施...
Python可以使用爬虫技术实现对网站目录下所有文件的遍历。首先,我们需要使用requests库发送HTTP请求,获取网站目录的页面内容。然后,利用BeautifulSoup库来解析页面内容,提取出所有文件的链接。接着,通过递归...
释放双眼,带上耳机,听听看...记录在爬取微博博主微博数据时使用Python3中Json数据遍历取指定值json地址遍历数据遍历json数据中"data"-"cards"-"mblog"-"page_info"-"media_info"下的视频链接地址,即"stream_url"中的...
目录应用目标思路分析1.扫描网段2.远程建立FTP连接3.遍历读取写入文件完整源码(可运行)写在最后 应用目标 1.扫描网段,获取其中所有的开放FTP服务的机器的IP地址 2.依次遍历获取每个FTP的文件 3.将文件名及文件...
从网上获取目标网站的数据一般通过网络爬虫的方式,但是这种方式往往可能效率比较低,而且有些网站可能会限制爬虫,比如著名的Github,当通过API爬虫的方式获取数据的时候,Github官方对爬虫速率进行了限制,超过了...

目录Beautiful Soup介绍Beautiful Soup 安装安装解析器Beautiful Soup 使用对象的种类Tagtag中重要的属性NameAttributesBeautifulSoup遍历文档树子节点获取Tag的名字.contents 和 .children父节点.parent.parents...
以下是一个简单的Python爬虫实例,用于从网页上获取图片并保存到本地: import requestsfrom bs4 import BeautifulSoupimport os # 定义要爬取图片的网页链接 url = "https://example.com" # 发送HTTP请求,获取网页...
深度优先遍历(Depth First Search, 简称 DFS) 与广度优先遍历(Breath First Search)是图论中两种非常重要的算法,生产上广泛用于拓扑排序,寻路(走迷宫),搜索引擎,爬虫等,也频繁出现在 leetcode,高频面试题中。...


爬取一个网站需要的所有网页
1.什么是爬虫爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来。想抓取什么?这个由你来控制它咯。比如...
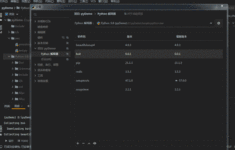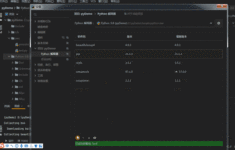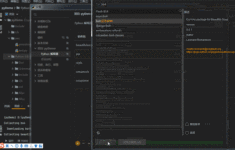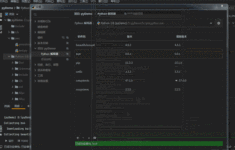
鉴于urllib请求模块的功能已经无法满足开发者的需求,出现了功能更强大的urllib3模块,urllib3模块是一个第三方的网络请求模块。 安装命令:pip install urllib3 1.发送网络请求 使用urllib3发送网络请求时,需要...

爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序。 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬...
python爬虫资源抓取--urllib/requests/requests-html、正则表达式、数据解析-Beautiful Soup/lxml/selectolax、自动化爬虫--selenium、爬虫框架--Scrapy/pyspider、模拟登录与验证码识别、autoscraper
这就是为什么这是一个练习使用 Python 抓取表格数据的好页面的原因。简单来说,我们逐行获取每一行,并找到里面的所有单元格,一旦我们有了列表,我们只抓取索引中的第一个(位置 0)并使用 .text 方法完成抓取元素...

【代码】python遍历一个目录,输出所有文件名。
python遍历文件夹列表 乱序
python文件夹操作,,1.遍历文件夹下所有1.遍历文件夹下所有文件2.将后缀为.DCM的文件复制到指定文件夹import osimport shutildef all_path(dirname): result = []#所有的文件 for maindir, subdir, file_name_list ...
推荐文章
- Android RIL框架分析-程序员宅基地
- Python编程基础:第六节 math包的基础使用Math Functions_ps math function-程序员宅基地
- canal异常 Could not find first log file name in binary log index file_canal could not find first log file name in binary-程序员宅基地
- 【练习】生成10个1到20之间的不重复的随机数并降序输出-程序员宅基地
- linux系统扩展名大全,Linux系统文件扩展名学习-程序员宅基地
- WPF TabControl 滚动选项卡_wpf 使用tabcontrol如何给切换的页面增加滚动条-程序员宅基地
- Apache Jmeter常用插件下载及安装及软硬件性能指标_jmeter插件下载-程序员宅基地
- SpringBoot 2.X整合Mybatis_springboot2.1.5整合mybatis不需要配置mapper-locations-程序员宅基地
- ios刷android8.0,颤抖吧 iOS, Android 8.0正式发布!-程序员宅基地
- 【halcon】C# halcon 内存暴增_halcon 读二维码占内存-程序员宅基地